Apache Kafka для початківців за 8 хвилин

Як виявити спробу шахрайства серед великого потоку транзакцій? Чи відстежити, як скоро приїде водій з Uber, щоб вийти заздалегідь?
Спершу уяви, скільки це інформації. На прикладі таксі: постійний збір та обробка даних про локацію водія; кожне оновлення місцеперебування збільшує загальний обсяг даних. А якщо врахувати кількість користувачів сервісу — генеровані дані зростають до неймовірних обсягів.
Тут знадобиться система, що може обробляти великі дані у реальному часі.
Коли справа доходить до біг дата, на сцену виходить Apache Kafka. Що це, для чого потрібно та як працює — розглянемо у цьому гайді для початківців.
Що таке Apache Kafka? Короткий огляд
Apache Kafka — це розподілена система обміну повідомленнями із відкритим кодом для обробки великих обсягів потоків даних у режимі реального часу. Вона поєднує високу пропускну здатність із низькою затримкою доставки даних. Написана на Java та Scala.
Kafka розробили інженери LinkedIn для обробки даних, генерованих платформою. Компанія хотіла зберігати та фіксувати всі дії користувачів: кліки, перегляди профілів, вподобайки та коментарі, щоб надавати більш персоналізований досвід.
Всередині Kafka — це розподілений лог, що дозволяє лише додавати дані у хронологічному порядку. Розподіленою Kafka робить той факт, що дані зберігаються не в одному місці, а розподіляються між різними серверами, що забезпечує високу доступність та продуктивність.
У 2011 році проєкт став опенсорсним, його передали Apache Software Foundation. З того часу Kafka стала дуже популярною. Її використовують розробники та дата інженери Netflix, Uber, Airbnb, Twitter та безліч інших компаній у сфері фінансів, ігор тощо.
Для чого застосовують Kafka Apache?
Інструмент корисний для відстеження дій користувачів, збору та моніторингу системних показників, створення стрічок новин, полегшення зв’язку між різними мікросервісами та інше. Розгляньмо деякі способи застосування.
Відстеження активності користувачів
Задача, для якої Kafka і створили. Активність користувачів — це дуже великий обсяг даних, адже кожен перегляд сторінки генерує багато повідомлень про активність. Це кліки, реєстрації, вподобайки, час перебування на сторінці, замовлення та інше.
Всі ці події зберігатимуться у Kafka, а інші пов’язані програми зможуть їх переглядати та обробляти.
Інтеграція даних
Інструмент інтегрує дані із багатьох джерел і систем. Так можна отримати безперебійний потік даних між різними програмами, БД та сервісами. Це забезпечує синхронізацію даних у реальному часі, конвеєри даних та керовану подіями архітектуру.
Агрегація логів
Інструмент збирає логи з різних систем та надає можливість їх обробляти, аналізувати та моніторити у реальному часі. Це дозволяє централізувати логи з розподілених систем, полегшуючи усунення проблем, аналітику та генерування сповіщень.
Обробка даних у режимі реального часу
Kafka дозволяє аналізувати потокові дані щойно вони надходять. Це можна робити за допомогою різних фреймворків: Apache Spark, Apache Flink або Kafka Streams.
Наприклад, це корисно для фінансових організацій для збору й обробки платежів та транзакцій. Так компанії зможуть миттєво виявляти шахрайські операції та блокувати їх, а також оновлювати дашборди з актуальними ринковими цінами.
У сфері логістики це допоможе моніторити та оновлювати програми відстеження, наприклад, для спостереження за переміщенням вантажу або за своїм замовленням з Glovo.
Інтернет речей (IoT)
Kafka може обробляти дані з датчиків, пристроїв і платформ IoT, забезпечуючи аналітику та інтеграцію з іншими системами. Наприклад, підійде для розумного дому, який отримує дані від термостатів, камер безпеки чи датчиків руху.
Обмін повідомленнями
Kafka може замінити традиційні брокери повідомлень, адже має кращу пропускну здатність, вбудоване розділення, реплікацію, відмовостійкість та кращі можливості для масштабування. Так можна полегшити обмін повідомленнями між різними системами та компонентами та забезпечити безперебійне спілкування між виробниками.
Звучить так, ніби вміння працювати з Apache Kafka — неминучість, адже вона має стільки корисних функцій. Це справді так, тул посилить твій стек. Проте не завжди Kafka є найкращим варіантом.
Наприклад, якщо є потреба обробляти до кількох тисяч повідомлень на день. Тут краще використовувати традиційні черги повідомлень по типу RabbitMQ. Також не варто використовувати цю систему для завдань ETL (extract, transform, load), адже перетворювати дані на льоту буде дуже важко. Для цього доведеться побудувати складний конвеєр даних, а потім підтримувати його.
Як влаштована та працює Kafka Apache
Архітектура Kafka складається з виробників (producers), брокерів (brokers) та споживачів (consumers). Kafka приймає потоки подій, написані виробниками даних та зберігає записи в хронологічному порядку в розділах (partitions) між брокерами — серверами.
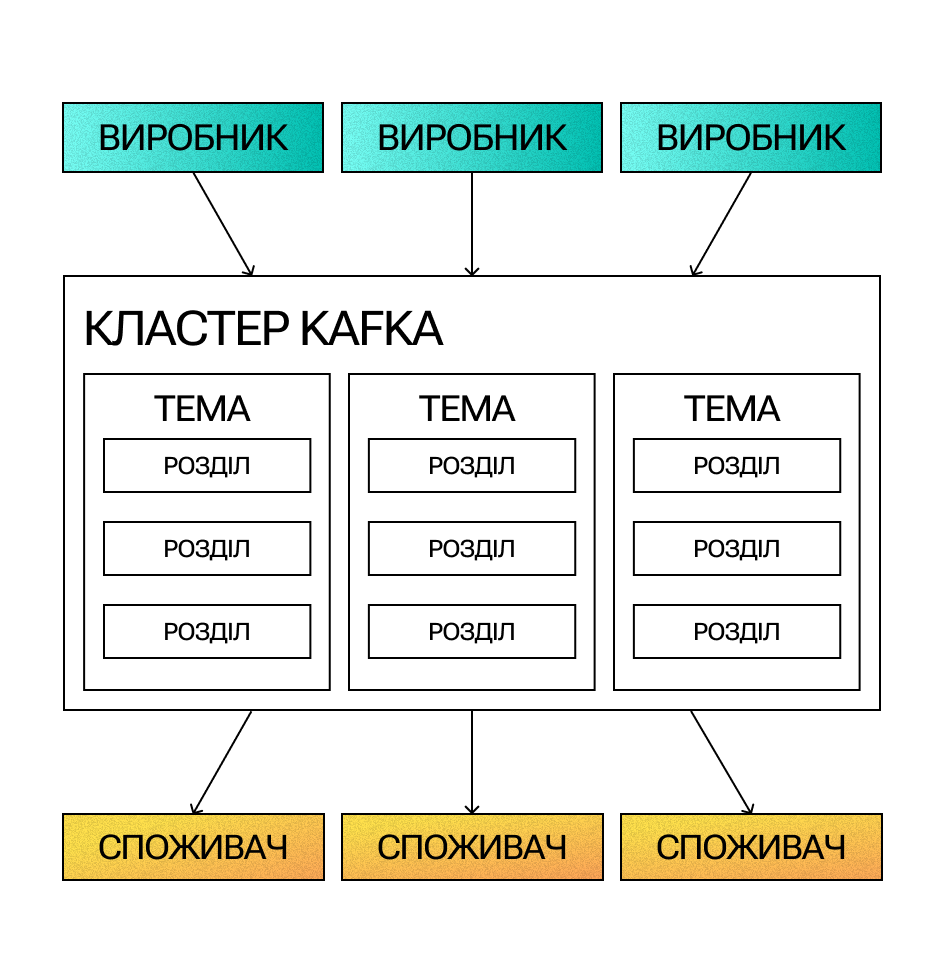
Розгляньмо основні поняття Apache Kafka детальніше.
Події (events)
Це повідомлення з даними, що описують подію. До прикладу, на сайті зареєструвався новий користувач. Тоді система створює реєстраційну подію, яка може містити його ім’я, імейл, пароль, локацію тощо.
Виробники
Все, що створює дані. Вони постійно записують події до Kafka. Виробниками можуть бути вебсервери, окремі компоненти програми, пристрої IoT та агенти моніторингу. Наприклад, датчик погоди, тобто пристрій IoT, щогодини створює «погодні» події, які містять інформацію про температуру, вологість та швидкість вітру.
Виробники публікують повідомлення на певні теми, а споживачі підписуються на ці теми, щоб отримувати повідомлення.
Споживачі
Це суб’єкти, які використовують дані, написані виробниками. Споживачами можуть бути однопотокові або багатопотокові програми. Буває так, що суб’єкт може бути одночасно і виробником, і споживачем. Це залежить від архітектури системи.
У Kafka кілька споживачів можуть формувати групи. Кожен споживач у групі обробляє певну кількість розділів тем, що дозволяє паралельно обробляти дані та балансувати навантаження.
Брокери та кластери
Брокери — це сервери, які зберігають та обробляють повідомлення виробників. Кожен брокер керує одним або кількома розділами.
Декілька серверів утворюють кластер, при цьому кожен з них знає, які розділи обробляють інші брокери у кластері.
Дані розподіляються між кількома серверами. А в кластері є ще кілька копій тих самих даних. Це робить Kafka стабільною, відмовостійкою та надійною. Якщо з одним сервером щось не так, нічого не загубиться, а інший сервер зможе виконати функцію несправного брокера.
Розділи (partition) та теми (topics)
Тема — це незмінний лог подій, який складається з потоків даних. Кожна тема поділена на розділи, і кожен розділ можна розмістити на окремому брокері.
Розділ — найменша одиниця зберігання. Вони ділять дані між брокерами для прискорення продуктивності.
Як вони пов’язані?
Кожен запис містить інформацію про подію та складається з пари ключ-значення. Kafka групує ці записи в теми (topics); споживачі отримують свої дані, підписавшись на потрібні їм теми.
Процес виглядає так: виробник публікує повідомлення, воно переходить до певного розділу залежно від значення ключа або рандомно. Кожне повідомлення у розділі визначається як окремий офсет, тобто має унікальне ID. Потім споживачі читають ці повідомлення з розділів.
Замість висновку: переваги Apache Kafka
Apache Kafka — популярна система для потокової обробки та аналізу великих обсягів даних. Її обирають завдяки:
- відмовостійкості, адже вона зберігає дані на різних серверах, а також реплікує їх;
- масштабованості, бо дозволяє просто додати більше машин у кластери;
- продуктивності. Генерувати та споживати дані можуть одночасно тисячі програм чи процесів;
- безпеці, оскільки вона передбачає різні інструменти для безпечної роботи. Наприклад, можна усунути можливість читання незавершених чи скасованих транзакцій;
- довговічності. Дані в Kafka можуть зберігатися протягом вказаного періоду: днів, тижнів, місяців;
- інтегрованості. Система має вбудований фреймворк Apache Connect, що дозволяє їй підключатися до баз даних, файлових та хмарних сховищ.
Kafka — круте доповнення твого стека, якщо хочеш працювати з великими потоками даних та стрімінговими архітектурами.
Ще більше інструментів та технологій DevOps — знайдеш на наших курсах для нової роботи. Бажаємо наснаги та нових скілів ✌️