Баги в ядрі Linux є непомітними протягом років

Дослідження 20-річної історії ядра Linux показало: у середньому помилки в коді живуть понад два роки, перш ніж їх знаходять і виправляють. Про це йдеться у звіті Pebblebed, автор якого проаналізував понад 125 тисяч виправлень у Git-репозиторії Linux.
Основою для аналізу стали коміти з тегом Fixes: — це стандартна позначка в ядрі Linux, яка вказує на коміт, де помилка була вперше допущена. Такий підхід дозволив точно визначити, скільки часу помилка залишалася в коді до моменту виправлення.
Скільки часу живе помилка в ядрі?
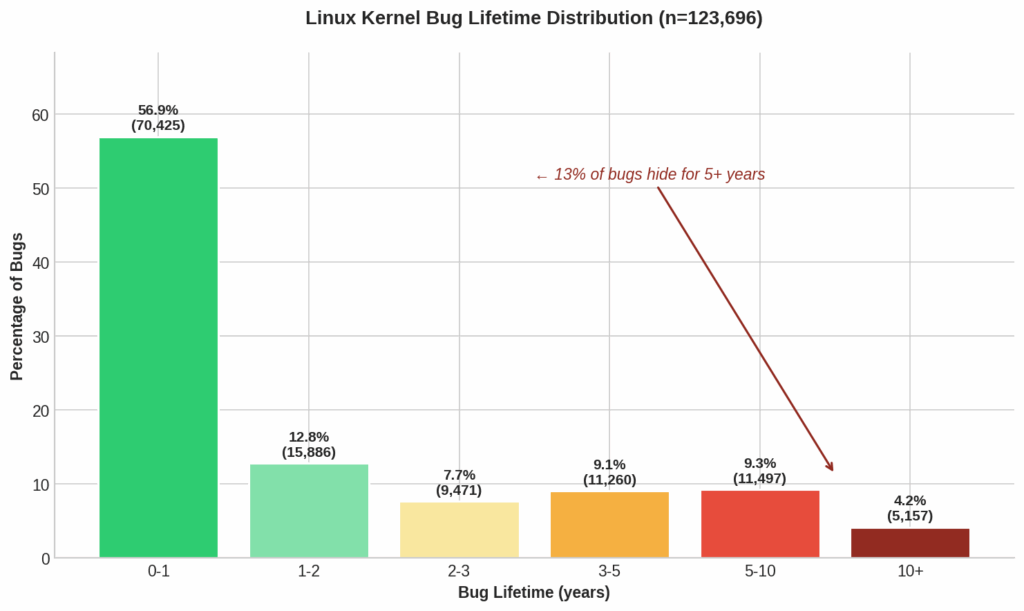
Аналіз повної історії ядра Linux з 2005 по 2025 рік показав:
- 125 183 зафіксовані пари «помилка-виправлення», з яких 123 696 мали коректні часові дані;
- середній час до виявлення помилки — 2,1 року, медіанне значення — 0,7 року;
- 57% помилок знаходять протягом першого року;
- 13,5% проблем залишаються непоміченими понад 5 років;
- 4,2% помилок існують більше ніж 10 років.
Найдовше зафіксована помилка — переповнення буфера в утиліті ethtool — перебувала в коді аж 20,7 року!
Окремий аналіз лише тих помилок, які були виправлені у 2025 році, дав іншу картину:
- середній час життя помилки зріс до 2,8 року;
- відсоток проблем, що залишалися непоміченими понад 5 років, сягнув 19,4%.
Дослідник пояснює це ефектом вибірки: у 2025 році виправляли як нові баги, так і велику кількість «історичних» проблем, накопичених за попередні роки.
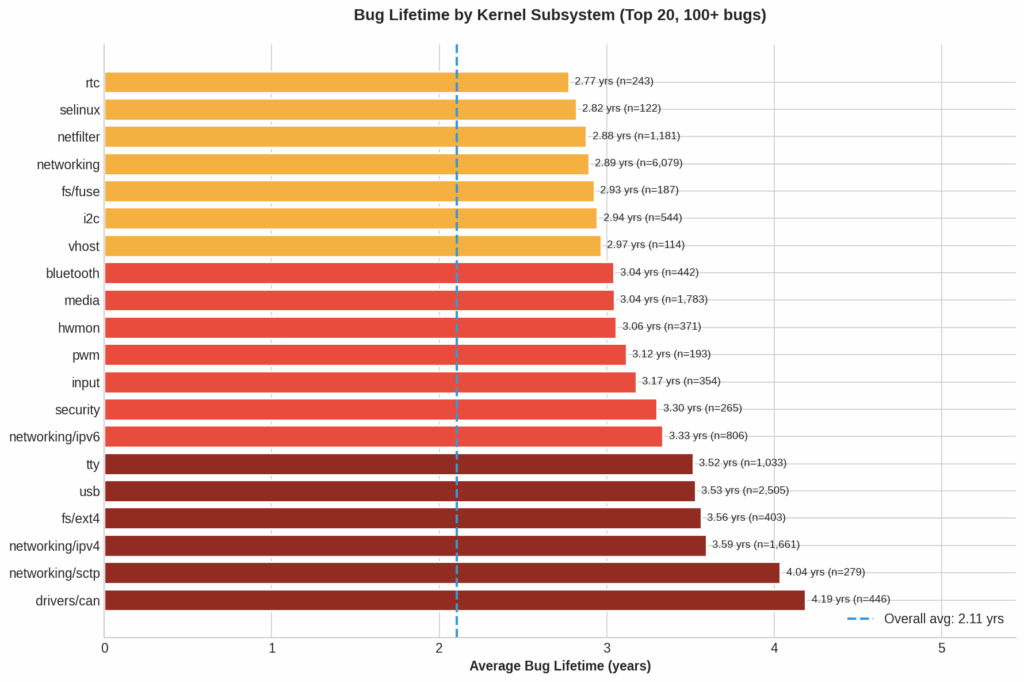
Не всі підсистеми однаково проблемні
Час, необхідний для виявлення помилки, значно відрізняється залежно від підсистеми ядра. Найгірші показники мають компоненти з меншою кількістю тестів і вузькою сферою використання:
- драйвери CAN-шини — у середньому 4,2 року;
- мережевий стек SCTP — 4 роки;
- IPv4-стек — 3,6 року;
- USB та TTY — приблизно 3,5 року;
- Netfilter і загальний мережевий стек — 2,9 року.
Для порівняння, помилки в підсистемах GPU та BPF знаходять значно швидше — у межах 1-1,4 року. Дослідження пов’язує це з активним використанням фазингу та спеціалізованої інфраструктури для тестування.
Які типи багів ховаються найдовше?
Не всі помилки однаково помітні. Найбільше часу на виявлення потребують:
- race condition — у середньому 5,1 року;
- integer overflow — 3,9 року;
- use-after-free — 3,2 року;
- memory leak — 3,1 року;
- buffer overflow — 3,1 року.
Причина у складності відтворення. Багато з цих проблем проявляються лише за специфічних умов: певної послідовності подій, навантаження, тиску на пам’ять або паралельного виконання коду.
Інструменти впливають на ситуацію
За останні роки швидкість виявлення помилок у ядрі Linux суттєво зросла. Якщо у 2010 році жодну нову помилку не виявляли протягом першого року, то у 2022 році цей показник сягнув 69%.
Ключову роль у цьому зіграли:
- фазер Syzkaller, який активно використовується з 2015 року;
- санітайзери KASAN, KMSAN та KCSAN;
- розвиток статичного аналізу;
- збільшення кількості рев’ю коду та контриб’юторів.
Водночас дослідження показує наявність значного беклогу: серед багів, виправлених у 2024-2025 роках, близько 18% були створені 5-10 років тому, а 6,5% — понад 10 років тому.
Машинне навчання для прогнозування вразливостей
Зібрані дані стали основою для створення ML-моделі VulnBERT, яка аналізує коміти та оцінює ймовірність внесення вразливостей ще до злиття змін у код.
Під час тестування на комітах за 2024 рік модель показала:
- 92,2% повноти виявлення помилок;
- лише 1,2% хибних спрацьовувань;
- значно кращі результати порівняно з класичними моделями на базі CodeBERT.
Модель не замінює рев’ю коду, але допомагає сфокусувати увагу розробників на найбільш ризикових змінах.
Цікаве спостереження
Майже 30% помилок у ядрі Linux з часом виправляють ті самі розробники, які їх і допустили.
Це підкреслює важливість довгострокового володіння кодом і знання внутрішньої логіки підсистем, особливо для складних і стабільних частин ядра.
Чому це має значення для індустрії?
Ядро Linux лежить в основі серверів, хмарних платформ, контейнерних середовищ, пристроїв Android та вбудованих систем. Кожен день, коли помилка залишається непоміченою, збільшує ризики для безпеки та стабільності інфраструктури.
Дослідження Pebblebed показує: інструменти пошуку помилок стають ефективнішими, але складність ядра та накопичений код означають, що повністю автоматизувати процес неможливо. Саме тому поєднання автоматичного аналізу, фазингу й експертного рев’ю залишається критично важливим.
- Реєструйтесь на курси Linux, щоб розуміти систему краще чи опанувати її з нуля. Так ви гарантовано знизите рівень своїх помилок