Збій AWS: коли хмара перестає бути надійною?

Понеділок для багатьох користувачів почався не з кави, а з повідомлень про те, що не працює Snapchat, зависла Canva, або Alexa не відповідає. Масштабний збій Amazon Web Services (AWS) став причиною того, що десятки популярних сервісів по всьому світу опинилися офлайн.
Що сталося?
Близько 15 тисяч користувачів із різних країн одночасно повідомили про проблеми з доступом до сайтів і застосунків, які працюють на базі AWS. Найбільше постраждав регіон US-EAST-1 — один із ключових центрів обробки даних Amazon на східному узбережжі США.
На сторінці статусу AWS компанія підтвердила підвищені помилки та затримки в роботі кількох сервісів, зокрема Amazon Elastic Compute Cloud (EC2), Elastic Kubernetes Service (EKS), DynamoDB, CloudFront та CloudWatch.
Інженери Amazon заявили, що «активно працюють над усуненням проблеми та з’ясуванням причин».
Згодом компанія повідомила про можливу першопричину — збій у DNS-резолюції API DynamoDB, який викликав хвилю помилок у пов’язаних сервісах. Через це система працювала з помітними затримками, а користувачі по всьому світу втратили доступ до застосунків.
Хто постраждав?
У списку постраждалих — десятки популярних платформ, серед яких:
- Snapchat, Signal, Viber, Zoom, Duolingo, Canva, Robinhood, Coinbase
- Fortnite, Roblox, PUBG, Epic Games Store, Wordle, Rainbow Six Siege
- Amazon.com, Prime Video, Alexa, Ring
- Netflix, Apple TV, Crunchyroll, The New York Times, McDonald’s App
CEO Perplexity AI підтвердив, що їхній сервіс також тимчасово зупинився через проблеми в AWS. Подібні повідомлення надходили і від інших компаній, які використовують Amazon як основну інфраструктуру.
Як збій в AWS вплинув на весь інтернет?
AWS — це не просто хмарне сховище, а глобальна екосистема, яка живить більшу частину сучасного інтернету. На її базі працюють медіа, мобільні застосунки, корпоративні системи, ігрові сервіси та платформи зі штучним інтелектом.
Тому навіть локальний збій в одному дата-центрі може спричинити ефект доміно: зависають бекенди, падають API, не проходить авторизація користувачів.
Регіон US-EAST-1 — один із найстаріших і найбільш завантажених у мережі Amazon, тому будь-які проблеми там мають глобальні наслідки.
Подібні інциденти вже траплялися — у 2021 та 2023 роках AWS переживала серйозні перебої. Але цього разу збій торкнувся не лише корпоративних систем, а й застосунків, якими користуються мільйони людей щодня.
Що зараз і які висновки?
Через кілька годин після інциденту Amazon повідомила про перші ознаки відновлення, проте попередила, що запити можуть продовжувати падати, а обробка даних — затримуватись. Деякі сервіси поступово повернулися онлайн, але повна стабілізація може зайняти більше часу.
Інженери AWS уже почали внутрішнє розслідування, щоб запобігти повторенню ситуації. Для DevOps-команд цей інцидент — чергове нагадування:
- не варто покладатися на одного провайдера;
- архітектура має бути багаторегіональною;
- критичні сервіси потребують резервного плану відмовостійкості.
Реакція в мережі
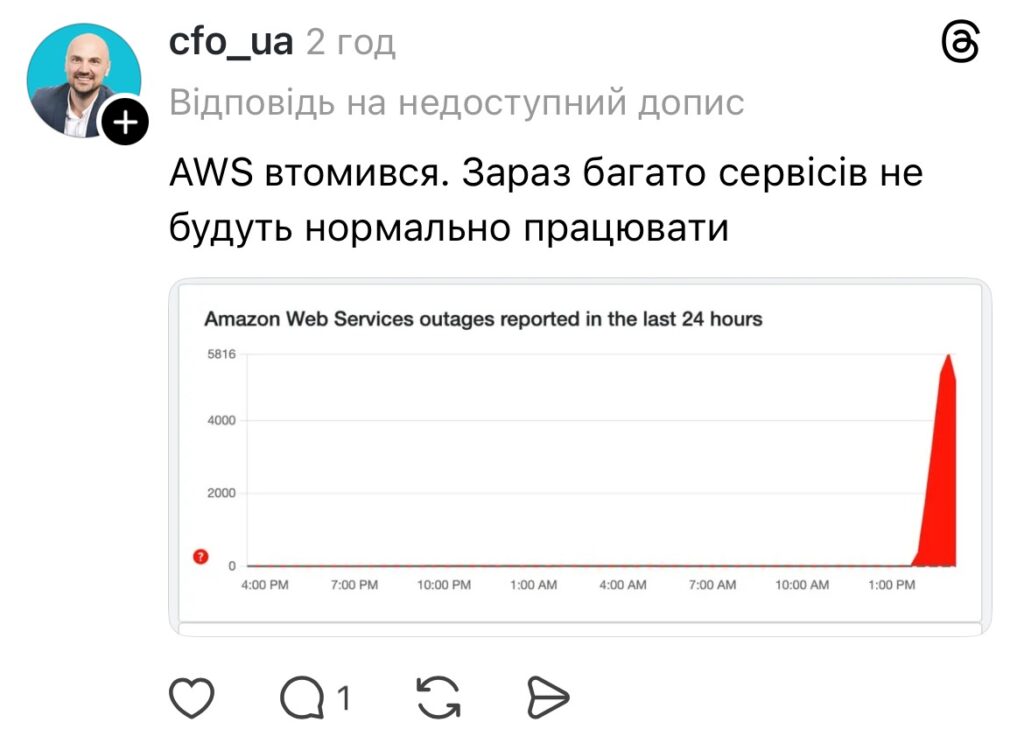
Поки Amazon боролася зі збоєм, у соцмережах з’явилися сотні постів і коментарів. Користувачі відреагували з іронією, як це часто буває у випадках великих технічних падінь.
Такі реакції лише підкреслюють, наскільки AWS став невидимою частиною повсякденного цифрового життя, навіть для тих, хто не працює в ІТ.

Висновок
Інцидент з AWS довів: навіть хмарні гіганти не застраховані від технічних помилок. Один збій у дата-центрі — і десятки глобальних платформ виходять з ладу.
Для компаній це сигнал перевірити власну інфраструктуру, а для DevOps-інженерів — нагадування про важливість надійного моніторингу, дублювання сервісів і чітких планів аварійного відновлення.
Ще не приборкав хмару? Приєднуйся на курс Amazon Web Services. Практикум з адміністрування та налаштування інфраструктури — та покращуй навички, щоб упевнено працювати з AWS.