Chaos Engineering: контрольований хаос зробить DevOps сильнішим

Ти працюєш у Rozetka чи Prom. Заходиш у Slack в неробочий час через купу сповіщень. Виявляється, що користувачі сервісу відмічають вас в історіях та скаржаться, що не можуть нічого замовити.
Починаєш копатися у системі та розумієш, що проблема у сервері кешування. Сервіс не може підвантажити зображення кнопки «Оформити замовлення», тож користувачі після години мук вибору просто не можуть її знайти. Від маленької проблеми їхній досвід суттєво погіршився.
Разом з командою фіксиш проблему та на майбутнє додаєш текстовий варіант для всіх елементів інтерфейсу.
Прокидаєшся в холодному поту і радієш, що це все тобі наснилося, адже в компанії практикують хаос-інжиніринг.
Хаос-інжиніринг — метод тестування розподіленого ПЗ, який навмисно вводить у нього сценарії збоїв та помилки. Це дає перевірити його стійкість до випадкових збоїв, адже вони можуть спричинити непередбачувану реакцію застосунку. Інженери, що цим займаються, досліджують, чому це відбувається та покращують програму, щоб бути готовими до таких випадків.
Програми стають дедалі складнішими, й те, що для користувачів виглядає як моноліт, насправді об’єднує різні сервери баз даних, API, мікросервіси та бібліотеки. Все це може вийти з ладу будь-якої хвилини.
Щоб створювати стійкі застосунки та розв’язувати проблеми до їх виникнення, команди DevOps все частіше практикують хаос-інжиніринг.
Що це таке, як працює та як втілити, щоб покращити свій застосунок — розбираємося далі.
В чому суть?
Фахівці створюють контрольовану імітовану кризу, щоб перевірити нестабільну поведінку ПЗ. Все, що можливо передбачити: технічні, природні чи зловмисні події. Наприклад, землетрус, що вплине на доступність дата-центру, або кібератака.
Якщо за таких сценаріїв продуктивність програми падає або щось ламається, це дозволяє розробникам підвищити стійкість коду, щоб бути готовими до таких ситуацій в реальному житті.
Хаос-інжиніринг може передбачати випадкове вимкнення різних сервісів, щоб побачити, як система на це реагує. Так можна знайти помилки, про існування яких у компанії могли навіть не підозрювати.
Але звідки це все почалося?
Історія
Історія хаос-інжинірингу почалася у 2010, коли Netflix мігрувала зі своїх фізичних дата-центрів у хмару. Компанія переймалася з приводу того, що станеться, коли раптом якісь інстанси AWS вийдуть з ладу або якщо певні сервіси будуть недоступними.
Тому вони створили Chaos Monkey. Ідея програми була проста: вона випадково відключала різні системи.
Потім Netflix поділився цією практикою у своєму блозі. Вона захопила увагу компаній, які теж тоді мігрували в хмару або більше покладалися на хмарні API та внутрішні мікросервіси.
Пізніше компанія ще й відкрила код програми, що дозволило іншим бізнесам спробувати цей метод на власних продуктах.
Етапи хаос-інжинірингу
Сенс цього підходу не в тому, щоб дозволити таким Chaos Monkey пуститися берега і ламати все безцільно.
Навпаки, це все має відбуватися у контрольованому середовищі, а експерименти мають бути спланованими, щоб розуміти, які саме випробування програма витримає (або ні).
Для цього є визначений процес, що починається з визначення сталого стану системи та переходить до формулювання гіпотези і її перевірки. Потім йде покращення системи, щоб підвищити її стійкість.
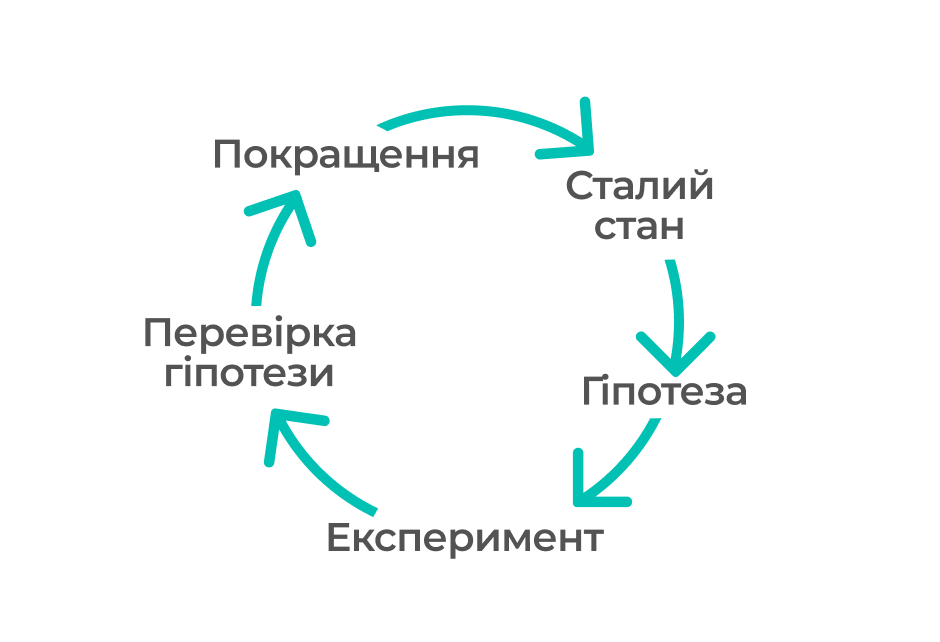
Сталий стан
Дуже важливо розуміти, як система поводиться у нормальних умовах. Так після штучно викликаної проблеми можна повернути систему у нормальний стан та впевнитися, що експеримент більше не впливає на її поведінку.
Тут головне зосереджуватися не на внутрішніх атрибутах системи на кшталт ЦП чи пам’яті. Потрібно щось вимірюване, що пов’язує технічні показники та досвід клієнтів. Щоб цей вимірюваний показник був у сталому стані, поведінка системи повинна мати передбачуваний шаблон, але суттєво змінюватися, коли у системі виникне збій.
Наприклад, для Amazon таким показником стала кількість замовлень, адже вона зменшується з кожною затримкою на сайті, що позначається і на доходах компанії.
Для Netflix це метрика на стороні сервера, що пов’язана з початком відтворення контенту. SPS (starts-per-second) означає кількість клаців користувача у його спробах відтворити відео. Цей показник має передбачувану модель та сильно змінюється під час збоїв. Його називають пульсом Netflix.
Ці два показники — стійкі, оскільки об’єднують досвід користувачів та операційні показники у єдиний вимірюваний та передбачуваний результат.
Тож вимірюй все, що можеш: мережу, машини та програми. Це допоможе відстежити відхилення від стабільного стану системи. Навіть якщо вони не змінюються, все одно можна помітити неочікувані взаємозалежності.
Гіпотеза
Коли зі сталим станом системи все зрозуміло, переходимо до гіпотез.
Що як зламається балансувальник навантаження? Або не працюватиме кешування? А якщо щось станеться з основною базою даних? Чи затримка збільшиться на 300 мс?
Обери одну гіпотезу та перевір її. І не ускладнюй, хай для початку це буде щось просте.
Можна почати з людського фактора. В будь-який момент з проєкту може хтось піти. Якщо команда не обмінюється знаннями чи не пише документацію, катастрофа може наступити ще до технічних збоїв.
Щоб це перевірити, треба визначити найбільш експертних спеціалістів на проєкті, на яких все тримається. Можна просто дати їм спонтанний вихідний. Результати таких експериментів часто бувають досить хаотичними.
Ось що ще можна робити. Щоб легше визначити гіпотезу, збери всіх причетних до продукту: розробників, дизайнерів, архітекторів менеджерів продукту тощо. Попроси кожного письмово відповісти на питання «Що буде, якщо …?». Часто буває так, що відповіді дуже відрізняються.
Обговори ці відповіді з командою, щоб зрозуміти їхнє бачення гіпотетичної ситуації. Врахуй всі ці наслідки у гіпотезі.
Розгляньмо на прикладі Amazon. Що як на головній сторінці не завантажуватиметься блок «Покупка за категоріями»?

Тут може бути багато варіантів:
- повернути сторінку 404,
- завантажити інші елементи сторінки, а на місці того блока залишити порожнє місце,
- інші блоки мають розтягнутися, щоб приховати помилку.
Це лише варіанти на стороні UI, а ще ж є серверна сторона. Саме тому хаос-інжиніринг такий корисний.
І ще один момент, який ти маєш пам’ятати: не працюй з гіпотезою, якщо знаєш, що певний інцидент зламає систему. Перевір ті частини застосунку, які вважаєш стійкими. В цьому і є сенс експерименту.
Сплануй та запусти експеримент
Хаос-інжиніринг перевіряє систему у будь-якому контрольованому середовищі — у деві, беті чи проді — за допомогою спланованого експерименту, щоб компанія була впевнена у своїй програмі. Ця впевненість і є ключовою для цього методу.
Команди можуть багато навчитися, ламаючи щось у невиробничому середовищі.
Домашнє завдання: спробуй виконати docker stop database у локальному середовищі та перевір, чи зможеш із цим впоратись.
Починай з малого, адже якщо одразу зламати щось серйозне, не факт, що компанія погодиться на майбутні експерименти.
Одна з найважливіших речей на цьому етапі — розуміння потенційного масштабу проблеми і як її можна мінімізувати. Подумай, як це вплине на користувачів, який функціонал та частини системи зачепить.
В ідеалі продумати, як зупинити експеримент, щоб якнайшвидше повернути системи у стабільний стан. Розглянь канаркове розгортання, щоб зменшити ризики збою. Воно означає поступове розгортання змін для невеликої кількості користувачів, а вже потім повільне розгортання цих змін для всієї інфраструктури та інших користувачів. Такий експеримент легше зупинити.
Це нагадує, як Instagram тестує нові функції: спершу вони доступні невеликій кількості користувачів, а потім вже всім.
Досліди та перевір
Щоб перевіряти, необхідно міряти: так можна кількісно оцінити результати. Починати найкраще з вимірювання часу виявлення проблеми. Враховуй ще, що системи моніторингу та оповіщень також можуть виходити з ладу. Тоді «системою оповіщення» стануть користувачі, як у страшному сні, за який ми писали на початку.
І не забувай про документацію. Напиши постмортем після експерименту. Будь максимально прискіпливим: детальний опис проблеми допоможе краще зрозуміти причину збою та запобігти схожій ситуації в майбутньому. Тож зроби документ з виправлення помилки (Correction-of-Errors).
В ньому пропиши:
- що саме сталося,
- як це вплинуло на користувачів,
- чому сталася ця помилка,
- чого це навчило,
- як запобігти такій помилці у майбутньому.
Відповіді на ці питання набагато складніші, ніж здаються спершу.
Постійне покращення
Сенс цього всього в тому, щоб першою чергою виправити знайдені проблеми, а потім вже розробляти нові функції.
Хаос-інжиніринг допомагає виявити непередбачувані проблеми у системі та виправити їх до того, як вони стануться у найменш слушний момент. А він завжди неслушний.
Успішна практика хаос-інжинірингу зазвичай приводить до більшої кількості змін, ніж очікувалося. І вони здебільшого культурні. Це допоможе змінити підхід з «Навіщо ти це зробив» на «Як ми можемо уникнути цього в майбутньому?».
Хаос-інжиніринг — ще один крок до успішної DevOps-культури у компанії. Тож підтягуй свої навички на наших курсах DevOps, крутіших за root права та перетворюй хаос на зону росту.